Разбираемся, что такое синтез речи и как это можно использовать на реальных примерах
 Автор:
Автор:

Выбор эксперта: программа для работы с голосом

Поможет обработать и улучшить сгенерированный материал

 Для Windows 10, 8, 7, XP
Для Windows 10, 8, 7, XP
Решение на базе нейросети для бизнеса и обычных пользователей

Удобное веб-приложение для TTS
Разбираемся с термином
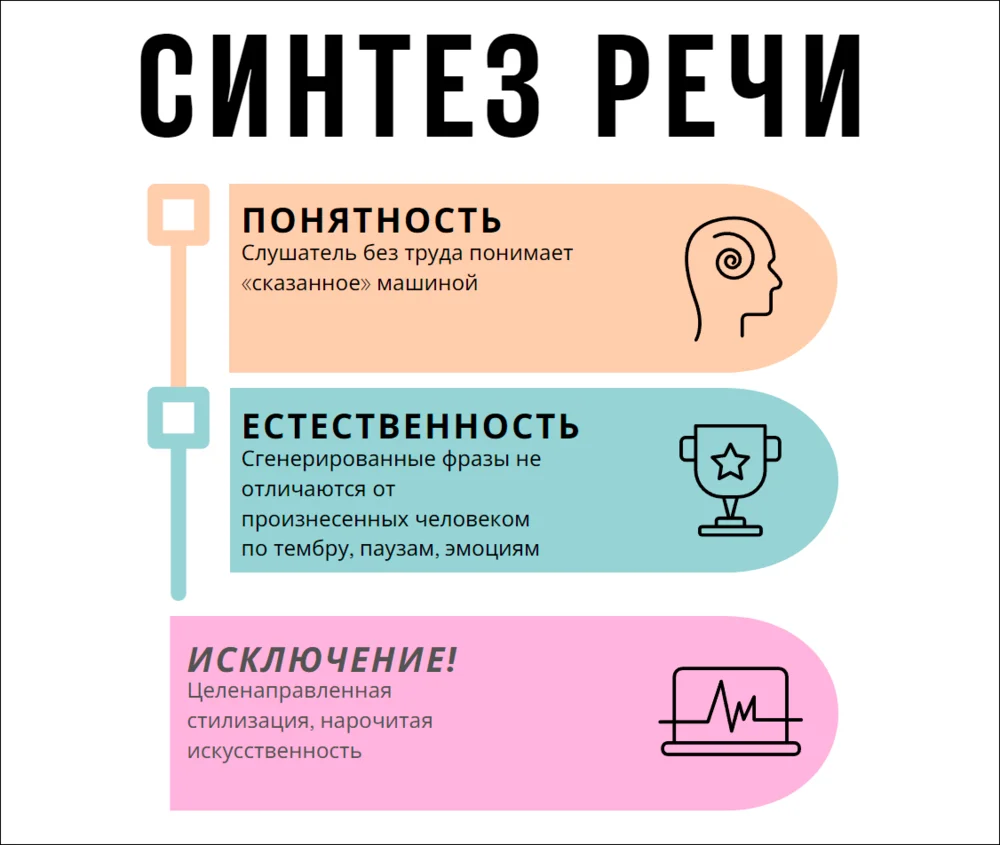
Речевой синтез — это искусственное моделирование человеческой речи. Сотрудники разработки стремятся к максимально качественной реализации двух задач:
- Понятность — каждый звук и каждое слово должны быть хорошо различимыми.
- Естественность — сгенерированные фразы должны звучать как речь обычного человека. Это может достигаться за счет верной расстановки ударений и акцентов, правильной имитации интонаций и эмоций.
Из этих правил могут быть исключения. Иногда, например, при записи озвучки для видео или музыкальных сэмплов, обычно требуется ярко выраженная стилизация. Роботу или фантастическому персонажу на экране порой вовсе не нужно разговаривать как человеку.
Как работает технология?
Первые попытки искусственно воссоздать человеческий голос предпринимались в конце XVIII века. Тогда для этого использовались комбинации акустических резонаторов, которые преломляли потоки воздуха от вибраций так, чтобы те имитировали несколько гласных звуков.
В 1930-х годах устройство было создано заново, но на электронных компонентах. Так появился вокодер — дословно «кодировщик голоса» (voice + coder — vocoder). Он состоял из системы генераторов звуковых волн и фильтров.
С конца 1950-х годов синтезирование начинает выполняться программно. Качественный скачок дала технология машинного обучения. Теперь насущной становится проблема, как отличить синтезированную речь от настоящей.
Независимо от реализации технологии, у нее есть два основных компонента:
- Голосовой движок — устройство или программа, которая генерирует звуки, похожие на речь.
- Интерфейс — способ взаимодействия с пользователем или оператором. Через него подается исходная информация в движок, а обратно поступают сгенерированные звуки.
Одним из основных направлений является преобразование текста в речь — text-to-speech (TTS). Пользователь вводит слова и после обработки запроса получает аудиозапись с озвучкой.
Виды TTS
Есть два метода TTS:
- Стандартный — создается через простые программы. Озвучка сильно отличается от голосов реальных людей по тембру, эмоциональным и интонационным окраскам. Такие ПО стоят дешево или распространяются бесплатно, не сильно нагружают компьютеры и мобильные устройства.
- Neural — озвучка генерируется нейросетью. На этапе обучения ИИ алгоритмы анализируют манеру речи и голоса других людей. Система подмечает любые особенности, что поднимает качество до недостижимого ранее уровня. Также технология позволяет клонировать тембры. Для этого достаточно настроить микрофон на компьютере и произнести несколько фраз с разными интонациями. Недостатками являются высокая стоимость софта и большой объем вычислений при генерации.
В первом случае не приходится переживать, как распознать синтезированную речь, а во втором можно запутаться.
Чем отличается компилятивная и параметрическая
модели синтеза речи?
TTS может основываться на двух моделях:
- Параметрическая — воссоздает голоса при помощи непрерывно меняющихся параметров звукового сигнала. Это усложняет синтезирование, но повышает его качество. Модель в том числе лежит в основе некоторых нейронных сетей. Одна из разновидностей метода — формантный синтез. Он пытается имитировать работу артикуляторного (голосового) тракта человека.
- Компилятивная или конкатенативная — фразы составляются из предзаписанных образцов (сэмплов). Минимальная длина любого из них — одно слово или фонема. Синтезирование не требует больших вычислительных мощностей, но его возможности ограничены объемом словаря — количеством готовых фрагментов. Высококачественного звучания добиться не получится, настройки произношения ограничены.
Какие задачи можно делегировать синтезу речи?
Синтез речи — это не простое преобразование текстов ради научных экспериментов. У технологии есть практическое применение, она уже прочно вошла в нашу повседневную жизнь. Вот лишь несколько распространенных сценариев использования:
- создание аудиокниг;
- машинная озвучка фильмов, сериалов, интернет-роликов, компьютерных игр, подкастов;
- генерация сэмплов и вокальных партий в музыке;
- создание музыкальных пародий (AI-каверов);
- голосовые ассистенты.
Как компании используют text-to-speech?
Качество синтеза достигло такого уровня, что позволяет постепенно отказываться от человеческого труда в отдельных сферах. Благодаря этому организации могут сокращать издержки, а людям не приходится выполнять рутинные и сильно изматывающие действия.
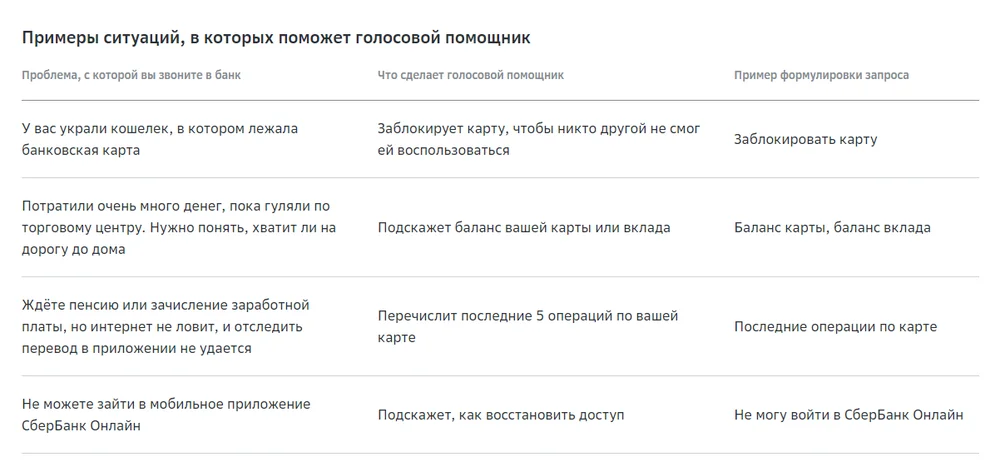
Сбер запустил голосового помощника. Виртуальная девушка обрабатывает свыше 65% обращений в службу технической поддержки. Они касаются типовых и достаточно простых проблем. Если ИИ не может решить вопрос, обращение перенаправляется специалисту-человеку.
Речевые оповещения есть у разной бытовой техники. Для роботов-пылесосов Xiaomi доступен выбор вариантов озвучки. Можно подобрать стиль уведомлений (шутливый или нейтральный) и более приятный тембр.

Яндекс предлагает комплексное решение для озвучки — SpeechKit. Оно нацелено на корпоративных клиентов. По сообщению разработчика, сервисом пользуются Литрес, Почта России, Додо Пицца и другие компании.
Какие факторы влияют на выбор технологии синтеза речи для
коммерческих продуктов?
Компании учитывают:
- Стоимость готового решения. Сюда входят затраты на покупку ПО, компьютеров и другого оборудования, настройку системы и ее дальнейшее обслуживание. Организация может выбрать решение с не такими совершенными лингвистическими моделями, но которое расходует меньше ресурсов инфраструктуры.
- Качество речевого движка. Оно влияет на репутацию бренда, удобство и лояльность клиентов. Пользователи предпочитают взаимодействовать с людьми и негативно воспринимают AI-ассистентов, даже если те действительно способны помочь. Правдоподобные интонации и тембры создают иллюзию живого общения.
- Простота и гибкость настройки. Задачи и подходы бизнеса постоянно меняются. У компании должна иметься возможность перенастроить алгоритмы без покупки дополнительных модулей или замены системы.
- Надежность. Система должна выдерживать высокие нагрузки и адаптироваться под нестандартные ситуации. Например, при нарушениях стандартных сценариев поведения пользователя.
Какие программы справятся с задачей?
Мы рассказали, что такое синтез речи в искусственном интеллекте. Теперь пришло время познакомиться с программным обеспечением, которое понадобится, чтобы использовать технологию для собственных задач.
Голосовые боты VoiceBox
Лучше справляется с: обработка заявок, техподдержка, оповещения клиентов, сбор обратной связи, обзвоны
Поддерживаемые языки: русский
Доступно в России: да
Система виртуальной телефонии для бизнеса. Компания-разработчик предоставляет номера, звонки на которые обслуживают голосовые роботы. Их поведение можно настраивать самостоятельно. Доступны два режима работы: использование предзаписанных реплик или генерация в реальном времени.
Плюсы:
- Система способна обрабатывать до 1 млн обращений в сутки.
- Поддерживает интеграцию с CRM.
- Есть приложения для Windows, iOS и Android, которые предназначены для настройки и мониторинга.
Минусы:
- Из-за высокой стоимости (рассчитывается индивидуально) не подходит для малого бизнеса и самозанятых.
- Предусмотрена авансовая оплата — при нулевом балансе (например, если деньги закончатся при неожиданном росте числа обращений) доступ приостанавливается.
SaluteSpeech
Лучше справляется с: озвучивание роликов, голосовые рассылки, анализ поведения сотрудников
Поддерживаемые языки: русский
Доступно в России: да
Инструмент от Сбера. Пользователям разрешается генерировать озвучку и запускать распознавание речи. Для последней в качестве источника звука можно подключить телефон к компьютеру как микрофон.
Организации могут использовать систему для рассылок и автоматизированных колл-центров. Алгоритмы умеют распознавать интонации. Это позволяет отслеживать настроение клиентов и своевременно запускать подходящие сценарии. Также система будет фиксировать случаи, когда сотрудники грубят пользователям.
Плюсы:
- Можно обозначать ударения, паузы, акценты и интонации при помощи языка разметки SSML.
- Озвучивание одного материала двумя голосами.
- Семь предустановленных мужских и женских тембров.
Минусы:
- Иногда не выполняется авторизация.
- Онлайн-версия на официальном сайте не всегда прогружается.
- Генерация без подключения к интернету доступна только на премиум-тарифе.
Yandex SpeechKit
Лучше справляется с: автоматизированные колл-центры, голосовые помощники, контроль качества сервиса
Поддерживаемые языки: свыше 15, включая русский
Доступно в России: да
Продвинутое решение для бизнеса. В основе лежат алгоритмы голосового ассистента Алиса. Предназначено для телемаркетинга, озвучки больших объемов контента и создания колл-центров. Дополнительно может отслеживать поведение персонала при взаимодействии с клиентами.
Плюсы:
- 15 встроенных тембров, можно создавать собственные голоса.
- Допускается устанавливать и запускать без выхода в интернет.
- Предоставляется подробная документация к API (цифровым библиотекам и интерфейсам).
Минусы:
- Обычным пользователям доступна только онлайн-версия для озвучки текстов до 500 знаков.
- Конфигурация и стоимость конечной системы определяются по запросам после согласования с разработчиком.
Robot Talk
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, английский
Доступно в России: да
Простая программа для синтезирования речи. Использует движки, которые изначально встроены в ОС. Сгенерированные материалы можно сохранять как аудиофайлы.
Плюсы:
- Регулировка громкости, высоты тона и скорости.
- Три формата — MP3, WMA и WAV.
- Есть версии на macOS, Android, iOS.
Минусы:
- Синтезирует в низком качестве.
- Интерфейс на английском.
АудиоМАСТЕР
Лучше справляется с: запись образцов для обучения ИИ, обработка сгенерированных материалов
Поддерживаемые языки: любые
Доступно в России: да
Удобный аудиоредактор. Понадобится, чтобы внести финальные штрихи в сгенерированную озвучку — проанализировать частоты на спектрограмме, выровнять громкость, обработать эквалайзером, наложить реверберацию и прочее. Также в программе можно записать образцы для дальнейшего клонирования голоса ИИ.
Плюсы:
- Простой и понятный интерфейс.
- Можно запускать на слабых ПК.
- Поддерживает популярные аудиоформаты — MP3, WAV, OGG, AAC и другие.
- Умеет извлекать звуковые дорожки из видео.
Минусы:
- Нет версии для Mac OS.
 Для Windows 11, 10, 8 и 7
Для Windows 11, 10, 8 и 7
APIHOST.RU
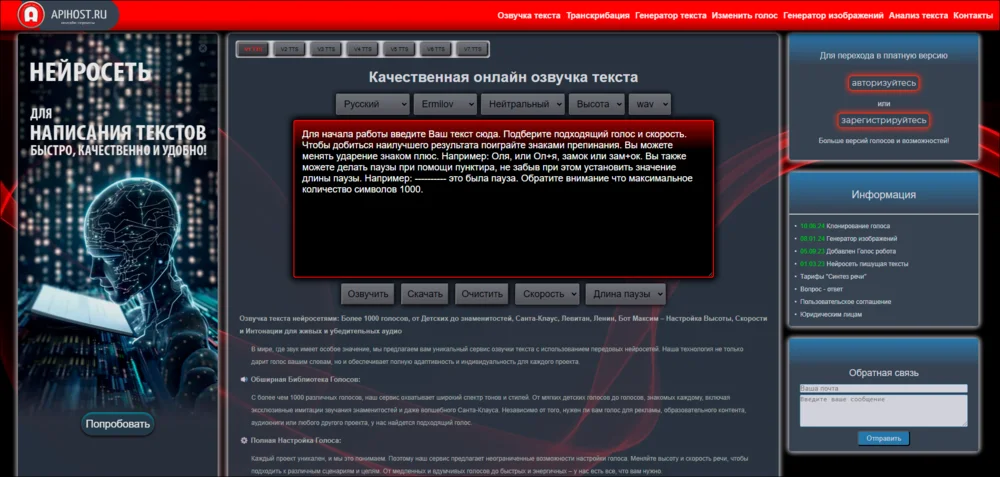
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, английский, испанский, португальский и другие
Доступно в России: да
Онлайн-сервис с синтезатором речи. Доступно семь версий движка — они различаются набором характеристик, голосов и поддерживаемых языков. После обработки запроса можно скачать сгенерированный звуковой файл.
Плюсы:
- Более 1000 тембров.
- При помощи специальной разметки можно менять ударения, указывать паузы.
- Скорость синтезируемой речи настраивается вручную.
Минусы:
- Языковые модели тарифицируются по отдельности, но подписка открывает доступ ко всем пресетам.
- Даже после долгой настройки не всегда удается добиться естественного звучания.
VoxWorker
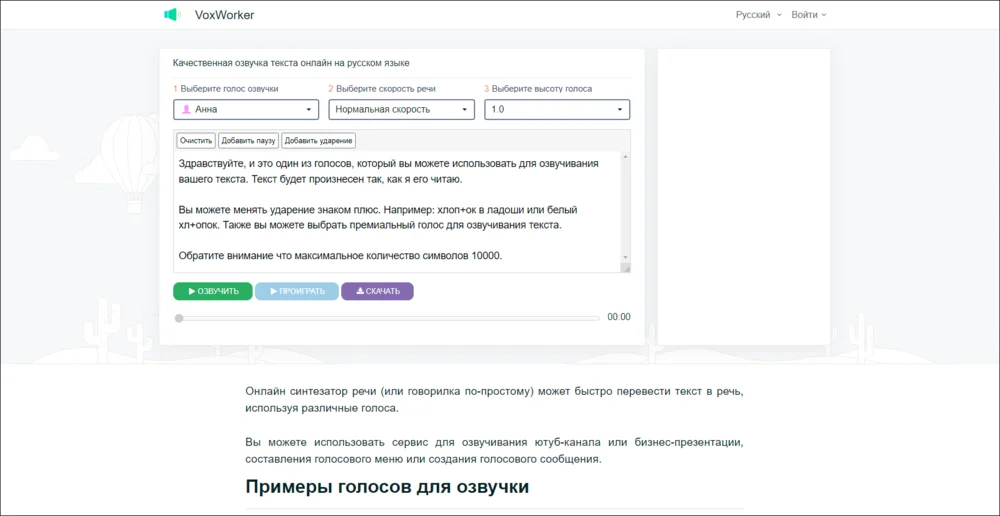
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, украинский, английский
Доступно в России: да
Этот сервис для TTS выдает разные MP3-файлы с озвучкой. Также можно воспроизводить синтезированные голоса только непосредственно на сайте. Также что решение подойдет не для всех задач.
Плюсы:
- Позволяет расставлять паузы и ударения.
- Можно бесплатно озвучивать до 5000 символов за раз и до 10000 в сутки.
- Настраивается высота голоса.
Минусы:
- Стоимость озвучивания для разных тембров не одинаковая.
- Нельзя хранить аудиофайлы на сервере. Без регистрации они удаляются через час, а после регистрации в сервисе — всего через 96 часов.
Narakeet
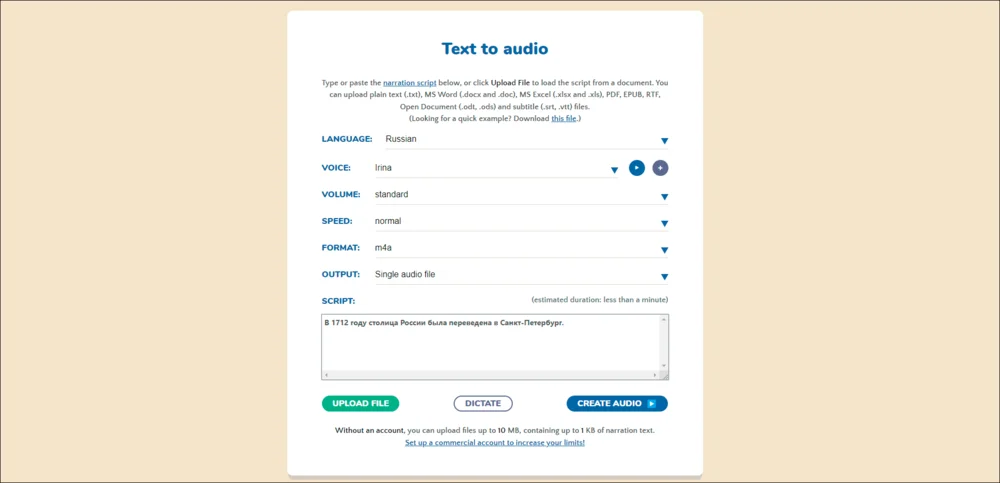
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, английский, корейский, французский и другие
Доступно в России: бесплатная версия, для покупки премиума нужен зарубежный платежный сервис
Сервис для озвучивания субтитров и текстов. Результат можно сразу воспроизвести или скачать в виде аудиофайла. Поддерживает регулировку скорости речи и автоматическое выравнивание громкости.
Плюсы:
- Десятки голосов для различных языков.
- Материалы можно загружать в виде документов (DOCX, DOC, PDF, XLSX и других) и файлов субтитров.
- Три аудиоформата — M4A, MP3, WAV.
Минусы:
- Интерфейс не русифицирован.
- Относительно высокая стоимость — от $6 за 30 минут.
QuData
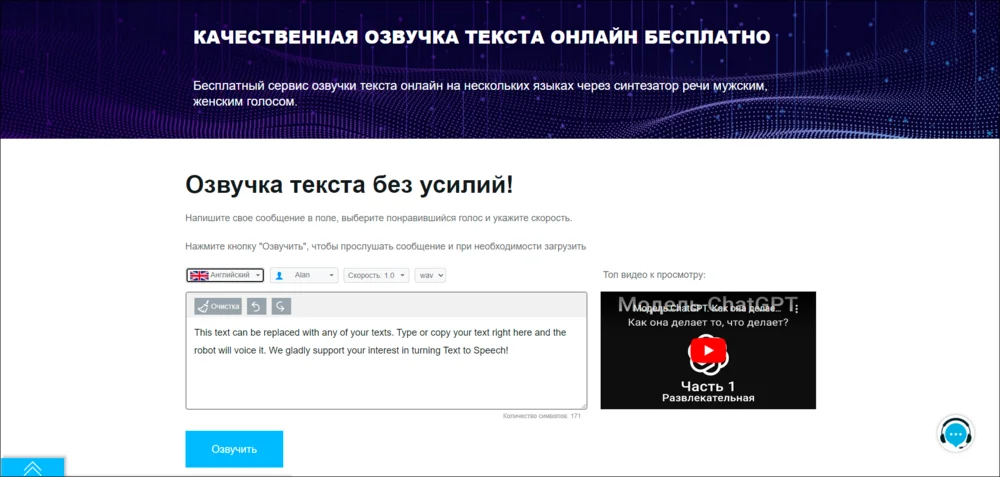
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, английский, португальский и другие
Доступно в России: бесплатная версия
Сервис функционирует по уже знакомому алгоритму. Необходимо добавить изначальный текст и запустить обработку. После этого можно скачать аудиофайл или воспроизвести результат.
Плюсы:
- Быстрая доступность — результатами можно делиться по ссылкам.
- Три аудиоформата — MP3, OGG, WAV.
- Несколько десятков голосов.
Минусы:
- Низкое качество синтеза.
- Минимум регулируемых параметров — только выбор скорости и тембра.
Texttospeech.ru
Лучше справляется с: озвучка текстов
Поддерживаемые языки: русский, английский, казахский, корейский и другие
Доступно в России: бесплатная версия
Онлайн-приложение для TTS. Тексты добавляются в специальную область на сайте. После предварительной настройки генерируется файл с речью.
Плюсы:
- Десятки встроенных тембров.
- Настройка скорости и высоты речи, громкости и реверберации.
- За раз можно обрабатывать до 20000 знаков.
Минусы:
- Материалы хранятся на сервере только 24 часа.
- Большая часть голосов платная.
- Нужна регистрация.
Подведем итоги
Мы рассказали про синтез речи, и теперь вы знаете, что это такое, как технология используется на практике. Разработчики стремятся к разборчивости и натуральности искусственных голосов. Существенного увеличения качества удалось добиться благодаря переходу на нейросети. На их основе создано несколько коммерческих решений, которые используются в колл-центрах. Они поддерживают построение сложных сценариев поведения.
Часто задаваемые вопросы
Проблемы вызывают вопросы лицензирования. Некоторые разработчики без разрешения копируют голоса актеров, дикторов и знаменитостей. Если вы сгенерируете тембр на основе собственной речи, нельзя исключать, что он может быть использован без вашего ведома, в том числе в противоправной деятельности.
Речь ИИ обычно выдают различные ошибки: неправильные ударения в простых словах и дифоны (переходы между фонемами), резкие перемены тембра, безэмоциональность.
Большинство систем для машинной озвучки предоставляют выбор из нескольких тембров.
В одном случае текст озвучивается нейросетью так, как его мог бы прочитать вслух человек. В другом — устная речь переводится в письменный текст, то есть выполняется транскрибирование.
Вас также может заинтересовать




- Преобразите запись голоса с посмощью эффектов
- Настройте темп, тон и тембр голоса вручную
- Создайте уникальный эффект присутствия
Для Windows 11, 10, 8, 7, XP